デジタル活用による鉄道サービスのスマート化
データ分析基盤/Big Data Discovery,NX Context-based Data Management System
鉄道や電力・ガスなどの社会インフラ分野や製造プラントを有する産業分野においては,データの利活用によるメンテナンスの高度化や最適なオペレーションの実現,新規サービスの創出に向け,IoT・ビッグデータ関連の業務への応用が期待されている。
Hitachi Data Science Platformは,顧客のデータ利活用をトータルにサポートする。具体的には,データを収集する環境の構築,データを一元的に収容するデータレイクの構築,利活用のためのデータの準備支援,AIやBIを活用したデータ分析サービス,およびアプリケーションの開発などが提供可能である。
本稿では,利活用のためのデータの準備支援に該当する製品であるBig Data DiscoveryとNX Context-based Data Management Systemについて紹介する。



現場で用いられる各種機器に設置されたセンサーから取得可能なデータ[OT(Operational Technology)データ]の形式は異種混合である。また,ITデータは業務システムごとに,同じ内容が異なるデータ項目や名称で管理されていることも多い。これらのデータをまとめて利活用するためには,データの統合,形式の統一,および単位合わせなどの事前準備が必要になる。
ユーザー部門がデータを利活用したい場合,必要なデータがどこにあるか分からないため,システム部門にデータ提供を依頼することになる。しかし,システム部門にとってもシステムがサイロ化しているため,データを収集するための負荷が高くなっている。
このようなデータ準備の負荷を低減するため,膨大で多種多様な形式の情報から効率的に目的のデータを抽出・作成できる「Big Data Discovery」(以下,「BDD」と記す。)と,利活用する側の視点でOTデータの構成を再定義して管理できる「NX Context-based Data Management System」(以下,「CDMS」と記す。)を新たに開発した。これにより,OTデータとITデータの統合的な分析・利活用の事前準備を支援する。
なお,BDDとCDMSは「Hitachi Data Science Platform」(以下,「DSP」と記す。)上の現場データ準備・可視化/管理サービス機能として提供する(図1参照)。
図1|DSP(Hitachi Data Science Platform)の全体図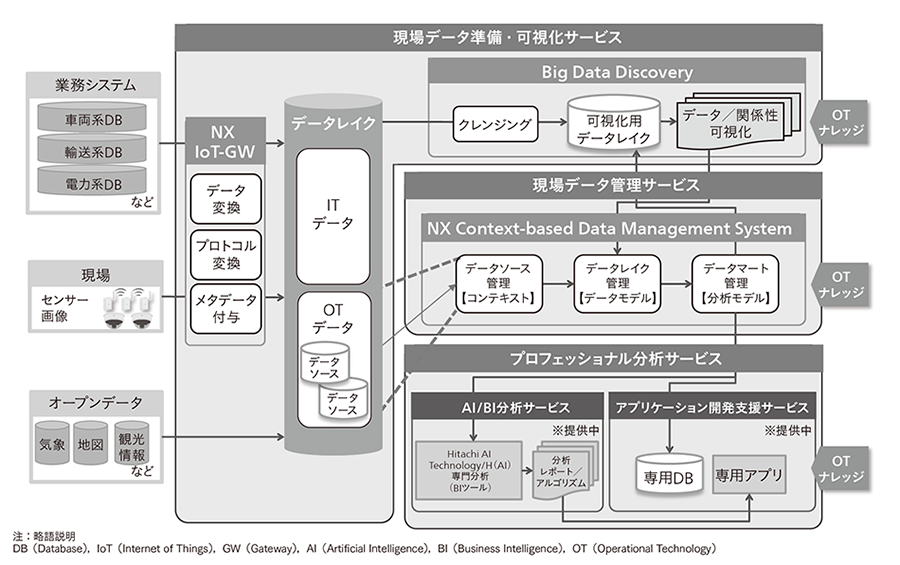 DSPは,顧客のデータ利活用をトータルにサポートするために3つのサービス/製品を提供する。現場データ準備・可視化サービスでは,プラント設備・機器などからセンサーデータを収集するNX IoT-GW機能と,収集されたOTデータやシステムから取得したITデータを対象に,データの関係性を自動で可視化して,利活用対象とすべきデータを高速に結合/抽出可能にするBDD機能を提供する。現場データ管理サービスでは,分析対象のデータを意味付け,モデル管理することで,現場データの利活用を容易にするNX-CDMS機能を提供する。また,プロフェッショナル分析サービスでは,DSPとAIやBIをシームレスに連携することで高度な分析を支援するサービスや,専用のアプリ開発を今後提供していく。
DSPは,顧客のデータ利活用をトータルにサポートするために3つのサービス/製品を提供する。現場データ準備・可視化サービスでは,プラント設備・機器などからセンサーデータを収集するNX IoT-GW機能と,収集されたOTデータやシステムから取得したITデータを対象に,データの関係性を自動で可視化して,利活用対象とすべきデータを高速に結合/抽出可能にするBDD機能を提供する。現場データ管理サービスでは,分析対象のデータを意味付け,モデル管理することで,現場データの利活用を容易にするNX-CDMS機能を提供する。また,プロフェッショナル分析サービスでは,DSPとAIやBIをシームレスに連携することで高度な分析を支援するサービスや,専用のアプリ開発を今後提供していく。
データを利活用する人が,データを自由に活用できるようにするためには,自分で必要なデータを取得できるようにしていくことが解決策の一つだと考える。そのためには,データを取得する手段が煩雑,データ取得処理の時間が長大といった課題を解決する必要がある。本章では,これらの課題を解決するための製品であるBDDについて説明する。
ユーザー部門がデータ利活用をしたい場合,データ管理部門ごとにデータ使用許可を取ったり,システム部門に依頼したりするなど,手続きが煩雑な状態である。この煩雑な手続きなどを通して,ようやくデータを入手できるようになるという現状の課題を解決するためには,データを1か所に集めて,どのようなデータでも統一的なインタフェースで,ユーザー自身でデータを取得することができるようになればよいと考える(図2参照)。
図2|データ取得手段の改善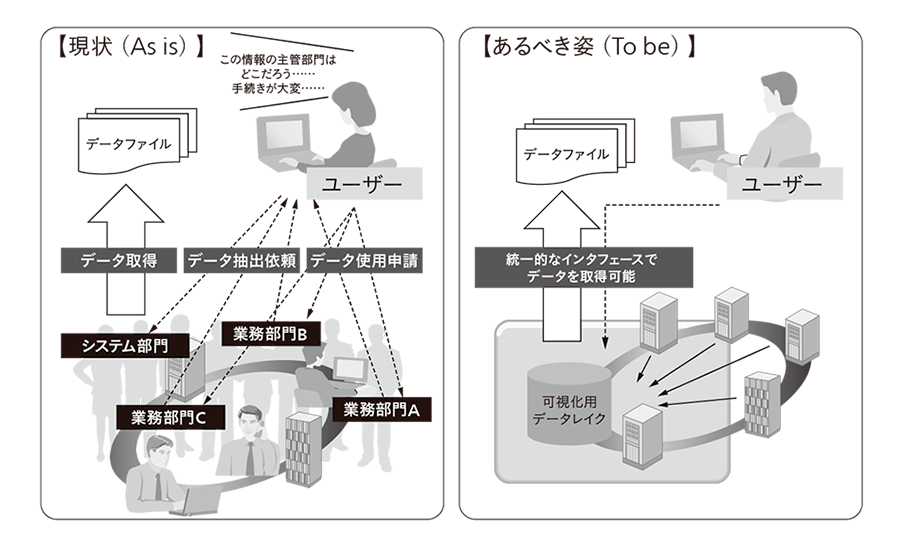 煩雑な手続きなどを通して,ようやくデータを入手できるようになるという現状を改善するには,どのようなデータでも統一的なインタフェースで,ユーザー自身でデータを取得することが可能になればよい。
煩雑な手続きなどを通して,ようやくデータを入手できるようになるという現状を改善するには,どのようなデータでも統一的なインタフェースで,ユーザー自身でデータを取得することが可能になればよい。
現状は,利活用のためのデータの生成は,システムごとに個別最適化された処理にて行っている場合が多い。データ容量の肥大化,出力するデータファイルの種類が多くなっているといった事情から,個々の処理能力が不足してきている。
ビッグデータを扱うシステムは,データ容量の増大に追随できるように処理能力を拡張しやすい構成が好ましい。分散処理技術を使って,高速にデータファイルの入出力ができる環境を構築することで,この課題を解決できると考える(図3参照)。BDDは,そのための製品として,日立の分散処理基盤製品であるHitachi Application Framework / Event Driven Computing(HAF/EDC)を使用している。
図3|データ取得処理時間の改善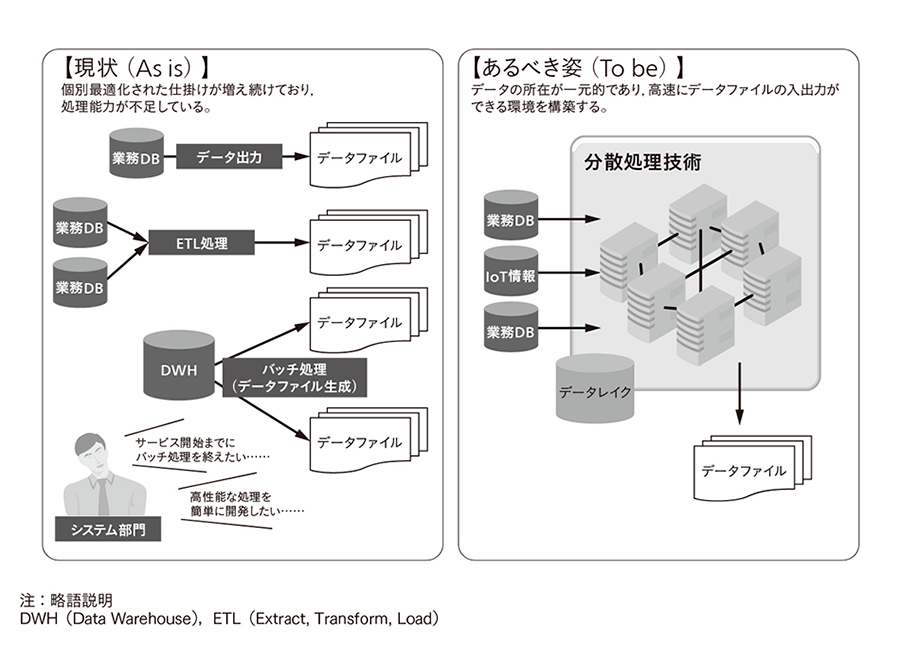 分散処理技術を使って高速にデータファイルの入出力を可能にすることで,「データ取得処理の時間が長大」という課題を解決する。
分散処理技術を使って高速にデータファイルの入出力を可能にすることで,「データ取得処理の時間が長大」という課題を解決する。
図4|データを「見る」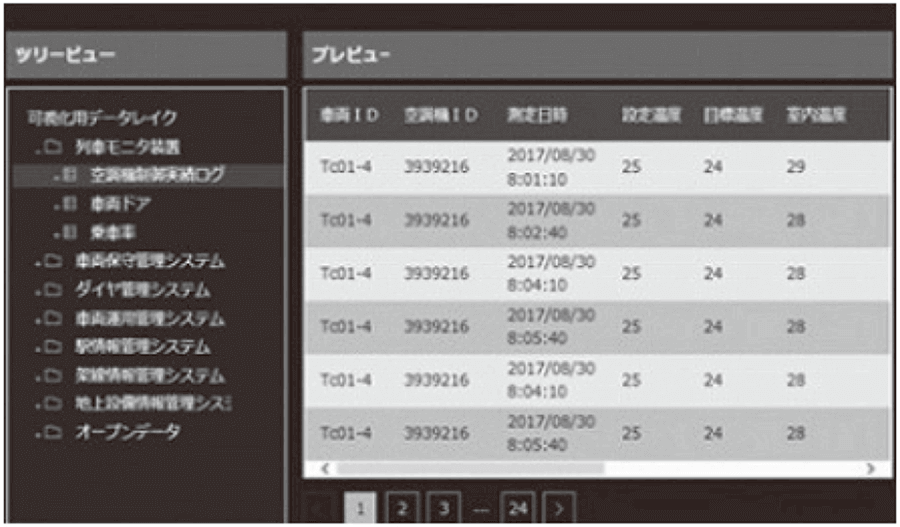 ビューアを使用してデータを見ながら有効なデータ項目を確認する。
ビューアを使用してデータを見ながら有効なデータ項目を確認する。
図5|データを「探す」 着目したデータ項目の名称をキーに,複数システムを横断したあいまい検索により有効なデータ項目を選定する。
着目したデータ項目の名称をキーに,複数システムを横断したあいまい検索により有効なデータ項目を選定する。
図6|データを「つなぐ」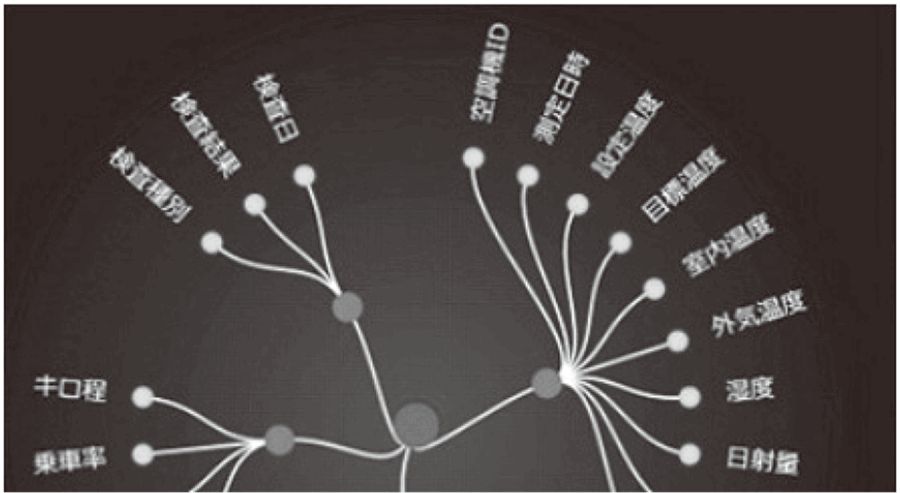 選定した結合キーで関係図や出現頻度,ヒストグラム,散布図などを確認し,利用価値があるデータ項目かどうかを判断する。
選定した結合キーで関係図や出現頻度,ヒストグラム,散布図などを確認し,利用価値があるデータ項目かどうかを判断する。
図7|データを「作る」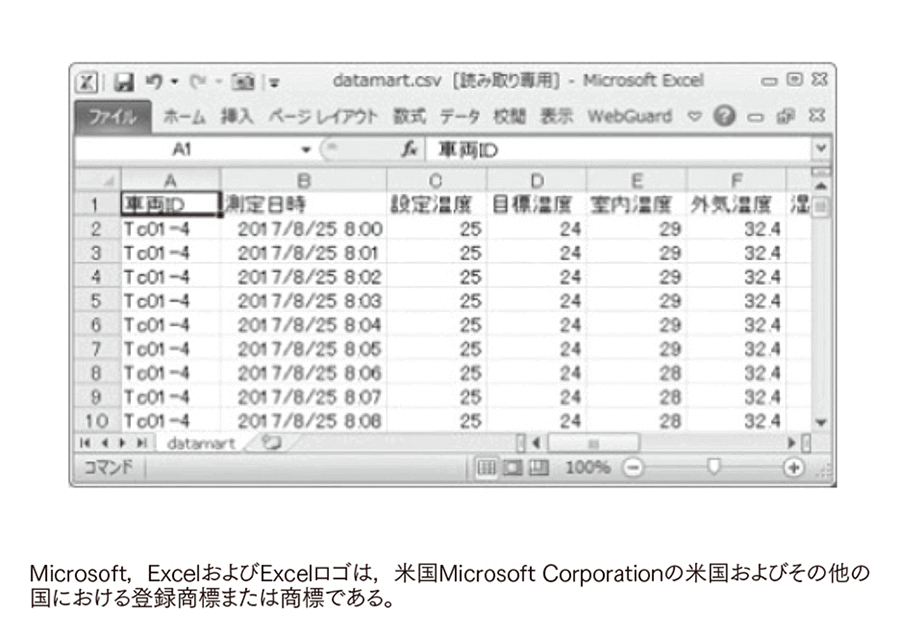 利用価値があると判断したデータを扱いやすい形で出力し,その後,分析活動などで利用する。
利用価値があると判断したデータを扱いやすい形で出力し,その後,分析活動などで利用する。
BDDは,異なるシステム間のデータの関係性を自動で表示する機能を備えており,収集した膨大なデータの中から,自分が着目したカラムと類似した名称のカラムを見つけ出すことが可能である。真に利活用対象とすべきデータを容易に抽出できるため,利活用のためのデータの準備に要する負荷を軽減し,本来の利活用作業などに迅速に取りかかることが可能になる。
BDDは,データを「見る」,「探す」,「つなぐ」,「作る」アプリケーションである。データ管理者がデータファイルを投入するだけで,利用者によるデータ確認(データを「見る」)や関係ネットワーク図表示(データを「つなぐ」)などの活動が自動的にできるようになる。
次に,OTデータのオフライン分析やオンラインアプリケーションへの適用に向けたデータ管理基盤について述べる。現場にある機器やセンサーは多種多様である。データを収集するタイミングや形式はセンサーごとに異なり,またセンサーを管理している現場システムもさまざまである。このためOTデータは,現場システムに精通する専門家にしか取り扱えなかった。OTデータを使用する分析者は,現場にどのようなデータがあるのか調査するのに時間がかかる。また現場システム運用者は,分析者が新しい分析を試みるたびに,OTデータを集めて提供するのが負担となっている。本章では,これらの課題を解決し,分析やアプリケーションを短期間で実現するための製品であるCDMSについて説明する。
CDMSは,データを「蓄積」,「体系化」,「利活用」の3段階で管理している(図8参照)。
図8|CDMSの構成 CDMSでは,データを「蓄積」,「体系化」,「利活用」の3段階で管理する。これにより,現場システムに精通していない分析者でもOTデータを容易に扱えるようになる。また,現場システム運用者は,新しい分析のたびに発生するデータの収集・提供が不要になる。
CDMSでは,データを「蓄積」,「体系化」,「利活用」の3段階で管理する。これにより,現場システムに精通していない分析者でもOTデータを容易に扱えるようになる。また,現場システム運用者は,新しい分析のたびに発生するデータの収集・提供が不要になる。
図9|データの体系化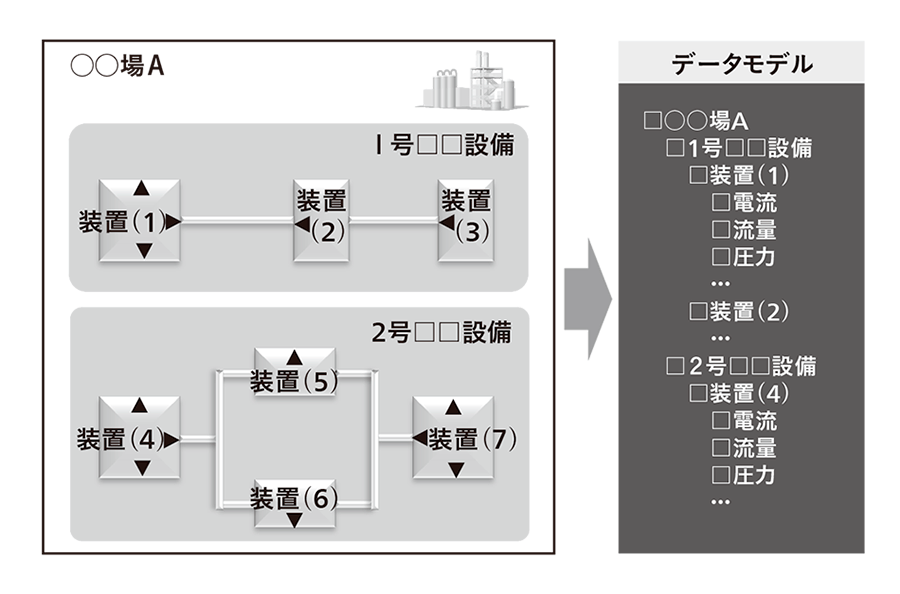 建屋の各設備・装置にどのようなセンサーが付いているのか,その構成を「データモデル」として定義する。分析者は,このデータモデルをたどることで,現場のどこにどのようなデータがあるのかを理解でき,目的のデータにアクセスできる。
建屋の各設備・装置にどのようなセンサーが付いているのか,その構成を「データモデル」として定義する。分析者は,このデータモデルをたどることで,現場のどこにどのようなデータがあるのかを理解でき,目的のデータにアクセスできる。
CDMSでデータを管理することで,OTデータの利用が簡単にできる。しかし,初めからすべてのデータを管理するための大きな投資は難しい。データ管理基盤には,運用をしながら段階的に拡張できることが要求される。
分析対象範囲を広げていくと,必要なデータが増加していく。また,新しい分析方法やアプリケーションを導入すると,今までとは異なる形のデータが必要になる。CDMSではGUI(Graphical User Interface)でデータソース,データレイク,データマートの定義をすることで,データの追加,新しい分析方法やアプリケーションの追加に容易に対応できる。
取り扱うデータの増加や分析アプリケーションの増加に伴い,サーバの処理量も増加する。分散処理基盤であるHAF/EDCを活用することで,CPU(Central Processing Unit)の能力拡張もシステムを停止することなく行うことができる。
生産性向上や収益増加といった新たな事業価値はデータ利活用を具現化した先にある。データ利活用に積極的な顧客は,PoC(Proof of Concept)の意味も込めて,個別のデータ分析活動を推進してきたが,その多くが単発的な活動で終わってしまった。その原因の一つに,本来のデータ分析の負荷よりもデータを準備する負荷の方が大きく,企業の持続的な活動としてなじまない点があったことは否めない。
データを利活用する人が,多数のデータの中から検索や可視化を行い利用価値のあるデータを発見し,扱いやすいデータを出力できるBDDを使って,データの準備の負荷を改善し,より高度なデータ利活用を実現することに貢献したい。
また,CDMSを使って,現場でしか分からないデータについて,あらかじめ適切な属性情報を付与しておくことで,データを利活用する側にもデータの意味が分かるようにし,OTデータの利活用が活発化し,事故数の低減などを実現することに貢献したい。
DSPを活用することで,BDDで新たな価値化データ構造を抽出して,CDMSで企業活動における継続的な価値化データ・分析サイクルの確立に貢献できるように,引き続きDSPの機能強化を図っていく。
